
The concept of “module” is quite old in software development, and the first real native support in a programming language probably dates back to the 70’s with the introduction of the Modula series. Most languages used in modern software development, such as Python, Java, Rust, Go and Javascript/Node.js to name a few, support this concept in one form or another as a native language feature. C++ has been the biggest absent in this list for a long time but with C++20 things have (hopefully) changed.
This article presents the theoretical aspects of modules with specific reference to C++ Modules and will be followed at some point with an evaluation of the state of the art in regards to their implementation across different compilers. Since this is quite a big feature with many concepts and rules to be digested, these articles are expected to be quite lengthy and will be split into multiple chapters.
1. Modules
A module, in its more general definition, is a self-contained entity that groups logically related objects and resources. Access to its functionality is allowed by means of well defined interfaces exposed by the module. This kind of abstraction makes modules the perfect building block for complex systems by providing high code re-usability and decoupling, the basis of modular programming.
In order to achieve this, a module must implement both logical and physical encapsulation. Logical in that it fulfills one of the first principles of good software design known as separation of concerns, where specific responsibilities are “encapsulated” within distinct objects, and physical in that internal information is not accessible nor visible to the clients of the module, which is a policy that should be enforceable directly by the language.
Objects inside a module can be entities such as classes, functions or “sub-modules” of some form.
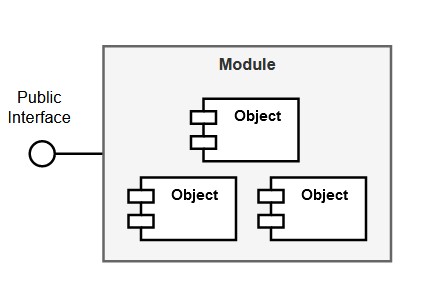
While C++ provides several features to implement modularization, they don’t fully achieve the potential of real modules as first-class citizens. Classes, for example, allow for too fine-grained encapsulation and can’t be used as larger higher-level units of abstraction. Namespaces are simply a code organization and name collision avoidance mechanism. And header files are merely a form of textual inclusion with no semantics for encapsulation whatsoever.
Even though there are well-established idioms for visibility management between components (Pimpl and abstract interfaces come to mind) and coding conventions for separating implementations from public interfaces (header/unit pairs, namespaced details to name a few), they do not provide the higher level of abstraction with strong encapsulation in a clean and efficient way as real modules with native language support can offer.
C++ 20 has finally introduced this feature after a very long process of standardization and we now have modules support as a core language construct.
2. Anatomy of a C++ module
A C++ module is made up of one or more translation units (TUs) with specific keywords for module declarations. Such translation units are called module units. Translation units that are not module units are considered part of the global module, which is anonymous with no interface and where regular non-module code lives. The general structure of a module unit is depicted in Figure 1, together with a standard (non-module) translation unit.
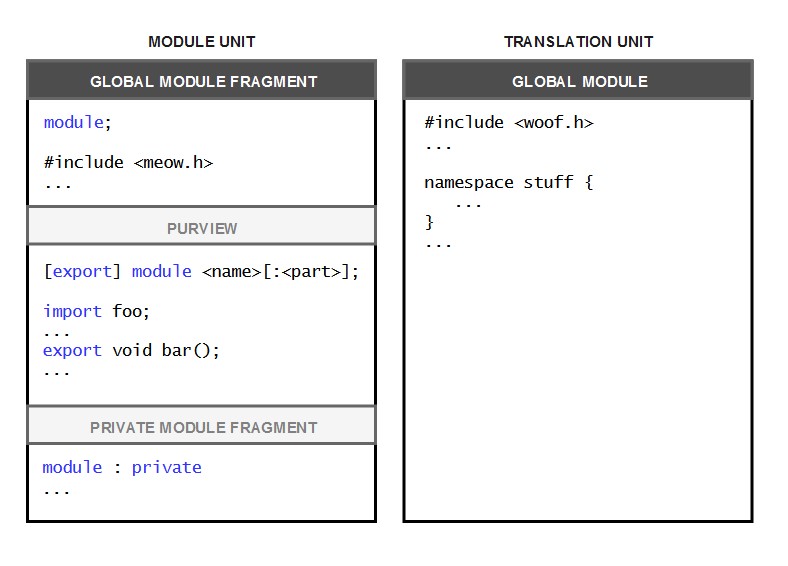
There are several sections that can appear in a C++ module unit, each one with specific purposes.
2.1 Global module fragment
This section must appear at the very beginning of a module unit and starts with a module; declaration. Only preprocessor directives shall be used in this section. Its purpose is, in fact, that of allowing the module to safely use legacy non-modular header files without polluting its scope and possibly breaking the code. All declarations here are not in the scope of the enclosing module unit (though accessible to it) but in the global module scope. To optimize the unit, only included entities that are actually referenced by the enclosing module unit (directly or transitively) are made available.
2.2 Purview
The Standard defines the purview as “the sequence of tokens starting at the module-declaration and extending to the end of the translation unit” (10.1.5). It is the section where exported entities (for module interface units) and other definitions and implementation details needed within the module are declared, depending on the type. It can be considered as the “main body” of the module unit. All declarations in this section are in the scope of the module unit.
The purview starts with a preamble introducing the module declaration [export] module <name>[:<part>]; followed by a sequence of import declarations. If the export keyword is used in the module declaration, the module unit is called a module interface unit, otherwise it’s a module implementation unit (more details below). A module partition can also be declared by appending a partition name :<part> to the module’s name. Note that including header files in this section is generally considered a bad practice as it would make all the included entities part of the module unit. The global module fragment should be used for this purpose.
2.3 Private module fragment
This section can only appear in primary module interface units, and if it’s present then the module unit in which it appears must be the only unit of the module. Its purpose is, in fact, that of encapsulating the interface and the implementation of a module in a single translation unit, without exposing the implementation detail.
Note that not all of these sections need appear in a module unit. The global and private module fragments are not necessary for a module to exist. The purview is the only required part.
3. Module units
Module units can be of different types, depending on how the module declarations are made.
- Module interface unit: this is a module unit whose declaration starts with the
exportkeyword (i.eexport module <name>;). This unit defines the public interface of the module and contains a number ofexportdeclaration for each entity that must be part of the public interface.- Primary module interface unit: a module can have only one module interface unit, which is called the primary module interface unit. However, the primary interface may be divided into parts called module interface partition units (discussed later).
- Module implementation unit: this is a module unit that contains implementation for the module functionality and doesn’t participate in the definition of its public interface. It is declared with
module <name>;and implicitly imports the primary module interface unit declarations, regardless of whether they are exported or not. Module implementation units cannot export declarations and cannot be imported. - Module partition unit: a module can be completely implemented in a single unit but in many cases it’s desirable to split it into several parts. A module partition unit is a part of a module declared with
[export] module <name>:<part>;. Entities declared in these units are only visible from other units within the same named module. Client code cannot directly import them. Module partition units can be of two types:- Module interface partition : these are module interface units declared with the
exportkeyword (i.e.export module <name>:<part>;) and represent part of the module’s public interface. The primary module interface unit must import and re-export these type of modules. - Module implementation partition : module implementation details can also be partitioned into several units declared with
module <name>:<part>;. Like module implementation units, it cannotexportanything. But unlike module implementation units, entities declared in implementation partitions can be shared with other units of the same named module by importing the partition (but cannot be re-exported).
- Module interface partition : these are module interface units declared with the
- Named Module: a module can be made up of several module units (i.e. the primary interface unit and one or more implementation/partition units) with the same
<name>. Collectively, they form a named module
Admittedly, this nomenclature is a bit overwhelming but it’s necessary to understand the different types of modules (or parts thereof) in order to be able to use them correctly and effectively.
In a general sense, module interface units are meant to define the public interface of the module, with interface partitions being a mean to facilitate its decomposition. Module implementation units provide the implementation for the interfaces, with implementation partitions being a way to share the internal details across several units.
4. The Binary Module Interface
The process of compiling a standard TU involves several processing steps, among which is the inclusion of header files. When an #include directive is parsed, the corresponding header file goes through a number of preprocessing phases (loading, character-mapping, tokenization, macro expansion, etc.) after which its contents are copied into the including TU. This is done recursively for all headers that are transitively included by the named header.
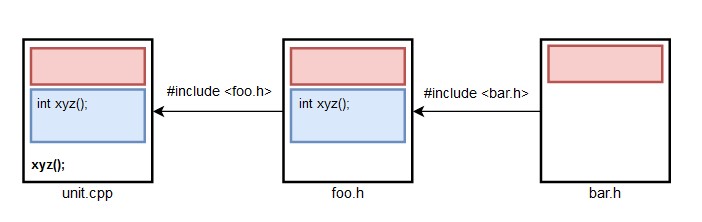
A consequence of this compilation model is that all of the contents in the headers are included into the TU, even if only a single entity is actually referenced. Since header files generally include other header files, a substantial amount of code can be propagated by this inclusion chain into the final translation unit.
If, for example, some unit.cpp includes <foo.h> because it needs function xyz() from that header, it will also get all the other entities declared in foo.h along with all those declared in other headers that are transitively included. The end result is that unit.cpp gets the union of the contents of all the headers in the chain, as depicted in Figure 2
Modules are special units that must be processed in a different way than standard translation units. A standard TU and a header file are two entities with no enforced relationship whatsoever. The separation with interfaces in headers and implementation in TUs is more of a convention. In fact, TUs may be used without header files. Modules, on the other hand, need an interface in order to be imported and used.
For this reason, when a module is compiled, two artifacts are created: an ordinary object file for linking, and a special file for its interface, called the Binary Module Interface (BMI). The BMI defines the entities exported by the module in a format that allows for easy and fast lookups. This format (along with the extension used for the BMI files) is not standardized and is, therefore, implementation-specific.
One advantage of this design is the ability to perform a “selective inclusion” of the entities that will be imported by consumers of the module. The BMI, in fact, functions as a sort of symbol table for all and only those entities that the module explicitly exports, as shown in Figure 3.
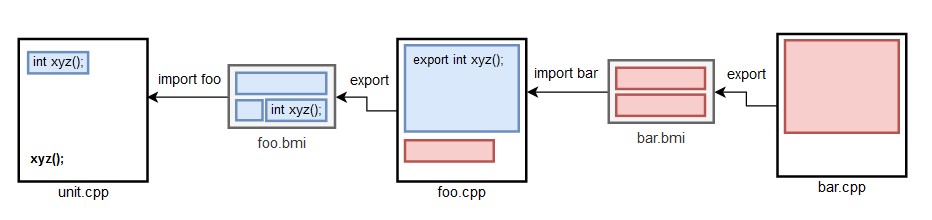
Let’s consider again the example presented above where unit.cpp imports module foo to use function xyz(). In this case only information about that function are available to the TU, not the whole content of the module. This is because only the entities explicitly exported by module foo are visible to the importing code, and only the entities that are actually referenced by the TU will be used. Also, if module foo imports some other module (e.g. bar) but does not explicitly exports its declarations, the contents of that module are not transitively propagated up to the TU.
While the BMI mechanism has its advantages, such as reduced code bloating and physical isolation from the imported module’s code, there are also some drawbacks. The most evident one is the introduction of strong dependencies between modules, as we’ll se in the next section.
4.1 Module dependencies
Since the contents of header files are simply pasted in the inclusion chains, there is a linear dependency of the TUs on such chains. This means that once a TU #include a header file, the dependency is completely determined by the mere existence of all the files in the chain and easily resolved by the compiler at the time the TU is compiled. This makes the build process highly parallel as the TUs can be independently compiled.
Importing modules, however, implies the presence of an entity that must be generated and compiled in a specific format (the BMI) in order for the modules to be usable. The consequence is that a module can’t be compiled if all the BMIs for the modules it imports are not compiled first.
For our example above this means that unit.cpp can’t be compiled without first generating foo.bmi, and module foo itself can’t be compiled without first generating bar.bmi from module bar.
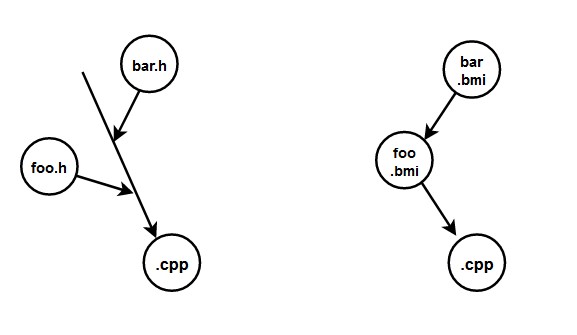
The current mechanism for module importation creates a dependency graph (more precisely, a DAG) that must be somehow resolved, as shown in Figure 4. While in a toy example like the one we used above this wouldn’t be an issue, for large applications with deep DAGs it may cause some complications with parallelism and the construction of the DAG itself.
In an ideal world, the usage of modules should not leak the complexity of the underlying implementation into the developers space. All that should be required is appropriate use of module-related syntax from which the modular structure can be inferred, as it’s done in other languages. Hopefully compilers and build systems will be able to automatically solve this problem.
5. Benefits
Despite the potential pitfalls, the (theoretical) advantages of this feature are manifold. Even though it seems they’re mostly seen as just a “replacement for header files”, in reality there is much more to that. Broadly speaking, C++ modules may bring a variety of benefits that can be classified into 2 main categories
- More efficient build process
- Better architectural abstractions
5.1 More efficient build process
Modules can greatly improve the efficiency (both in space and time) of the compilation process compared to header files due to a variety of reasons that are briefly summarized below.
- Space efficiency
- The same headers may be included multiple times across several TUs in a program. And since they are just copy-pasted text, multiple TUs including the same headers get the same duplicated code. This makes the TUs grow in size proportionally to the number and size of imported headers.
- Modules are compiled stand-alone units that are “linked” (not included) to client code thru the BMIs when required and only the needed symbols from the exported interfaces are used, not the whole modules code. This can greatly reduce the size of the TUs.
- Time efficiency
- Headers need to be parsed every time they are included in a TU, and processing a header file generates considerable overhead as the operations of character mapping, tokenization, macro evaluation, etc. are not cheap. This may heavily impact build times, especially when the same headers are included in many TUs. For m headers that are all included by n TUs that would be O(m x n) complexity.
- Modules do not require multiple parsing at build time as they are compiled only once to generate the BMI, which is then used for importations in constant time, that is the time of a name lookup, regardless of the size of the module. This may (in theory) reduce the complexity from O(m x n) to O(m + n) (in practice this depends on how the modules are processed by the build tools).
While this looks similar to the pre-compiled headers (PCHs) mechanism, the effects are different as PCHs still need to comply with the header inclusion model of C++, that is a linear dependency chain with no isolation which can still cause unwanted side effects (out-of-order inclusions, name conflicts, etc.). Also, PCHs are efficient mostly when there is a common set of big-sized headers that are included in a high number of TUs, so the benefits are mostly appreciated in very large code bases.
One important aspect to note is that module interface files (BMIs) are totally generated and managed by the compiler, as opposed to user-written headers. This means there is a lot of opportunity for compilers to do any sort of optimization, a burden that’s on the developer’s shoulders when writing header files by hand.
5.2 Better architectural abstractions
While the compilation benefits are already a big improvement, another advantage is the strong logical and physical high-level architectural abstraction they provide and that the .h/.cpp pairs simply can’t achieve. This brings huge benefits to the design of the applications, an aspect of software development too often overlooked.
The architectural benefits of modules stem from their strong encapsulation. Modules have well-defined semantic boundaries and provide fine-grained control over what is visible and what is not to the outside world. This avoids many of the pitfalls of header files caused by simply copy-pasting everything at the point of inclusion, which may affect the behavior of the code in many ways, depending on how such inclusion happens.
- Shielded interfaces: since the header files mechanism is based on simple textual inclusion, their code can interfere with the code of the importing units causing name collisions and potential changes to the meaning of interfaces. Modules, on the other hand, are imported using a symbol lookup mechanism that is not affected by declarations in the importing code.
- Better isolation: modules have strict scope, meaning that symbols they declare are visible to the outside world only if explicitly exported. This avoids unwanted implicit inclusions in importation chains and prevents implementation details from leaking in and out of the module.
- System Views: modules can be used to implement the concept of a “view”, that is a specialized or controlled access mechanism to information and functionality. In this sense, modules can act as views on parts of an existing system (subsystems) by encapsulating its functionality in order to abstract away complexity or to prepare it for gradual migrations towards a real modularized architecture.
- Microservices: one of the most popular design paradigms in modern software development is without doubts the microservice architecture. This kind of architecture is based on decomposability as the basis for its implementation. Modules provide a more robust and clean way to decompose large applications in order to make them microservice-ready.
All of these benefits mean better abstraction, which leads to improved designs and more robust architectures. One of the nice side-effects of this feature is that it forces the programmer into “modular thinking” by principle, which may help in writing better code.
6. Conclusions
This is undoubtedly a big feature that may allow writing more effective modular C++ code than with header files. Those who have been using modules in other languages may probably find the C++ implementation a bit “muddy”, and worry about the additional complexity it may bring to an already complex ecosystem (C++ et al.). And honestly, considering the potential pitfalls and the core design, I have some doubts as well.
In theory, we can see the many benefits they may bring in terms of compilation efficiency and improved designs. In practice, there are several factors that may render their implementation quite difficult with the consequence of adding too much complexity and the risk that a good chunk of it will be passed on to the developer. The second part of this lengthy article will deal with the implementation of modules in the major C++ compilers with a few real examples to see how much the practice resembles the theory.