The complexity of modern systems is driving radical changes in the software development world, with new paradigms and technologies continuously emerging in order to provide engineers with the right tools to deal with the challenges that such systems pose. Among the emerging practices, the following can certainly be considered as pillars of what we can call modern software development
- Microservices
- Containerization
- Serverless computing
- Continuous Integration, Delivery & Deployment
This article gives a broad outline of these new practices and tries to explain the fundamental ideas and core philosophy that motivate them, without any reference to specific implementations. As with any software engineering methodology, it is not exact science and many different points of view may (and do) exist, so the concepts exposed here are in no way meant to be taken dogmatically.
1. Microservices
A very common development style for building large software systems follows a modular design, wherein functionalities are grouped into entities with well-defined boundaries (modules) that provide some kind of service as part of the larger system’s business scope. From the point of view of the end user, how such modules are organized to form the system’s architecture is pretty much irrelevant. However, from the perspective of the developer it has a big impact on many aspects of the application, such as extensibility, maintainability, testability, scalability and performance.
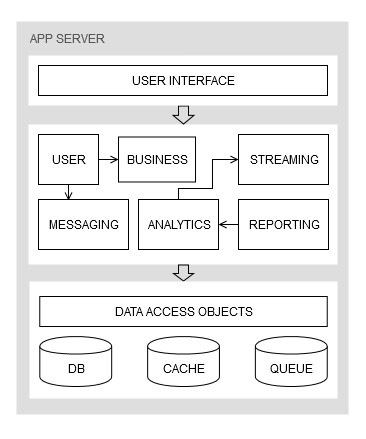
Traditionally, these software systems have been designed using a monolithic architecture, which is characterized by high locality of components, both at compile-time and at run-time. In these architectures all of the modules are located into the same compile-time unit, such as a directory tree on a disk, an archive file (WAR, JAR, ZIP), a “runnable” binary (EXE, DLL, etc.) and are executed within the same run-time environment (i.e. the same machine), sharing the same resources. Generally, software systems are also designed using a tiered (or layered) approach to achieve some degree of vertical decoupling, as depicted in the example of Figure 1.1
A consequence of this centralized design style is the tight coupling between all the modules providing the application’s services. Even though there may be good principles applied in order to achieve both vertical and horizontal decoupling, including but not limited to the tiered approach, modularity, SOLID, etc. and good separation of concerns, the fact that all the modules are dependent on the same language, stack and run-time environment makes them computationally and technologically coupled.
Computational coupling refers to the fact that service modules of a monolithic application run as a single process, or at most as different processes connected through IPC mechanisms in the same user-space and managed by the same machine, thus using the same underlying computing resources. This means that the execution of a service heavily affects the others since a failure in one of them (e.g. a memory leak, access violation, etc.) can potentially crash all those that are connected or even the whole system.
Technological coupling is given by the use of the same technology stack (language, framework, database, etc.), which may create mental barriers in the engineering teams by inducing a sort of “one size fits all” attitude that might prevent making sound design decisions. Furthermore, as the application grows in size and complexity, migrating to a more modern stack becomes exponentially more difficult. This entails the potential of being trapped with outdated technology and accumulating substantial technical debt.
A monolithic architecture will force all the teams to excessively focus on the whole system even when there is no need to. In fact, although there may be separate teams dedicated for each service, they all work on the same shared code base where making even small changes may create a ripple effect that disrupts other parts of the system due to technological coupling. This may cause teams to become poorly reactive, flexible and independent as they are constantly hung to what other teams are doing on other parts of the application.
Another big drawback of these architectures is the fact that they are not efficiently scalable. While it is easy to scale up a monolithic architecture by simply replicating (i.e. copying) the application to a new computational environment (server, VM, container) this approach is inefficient because if only one service requires additional capabilities, a full scale-up of the entire system may lead to a waste of resources.
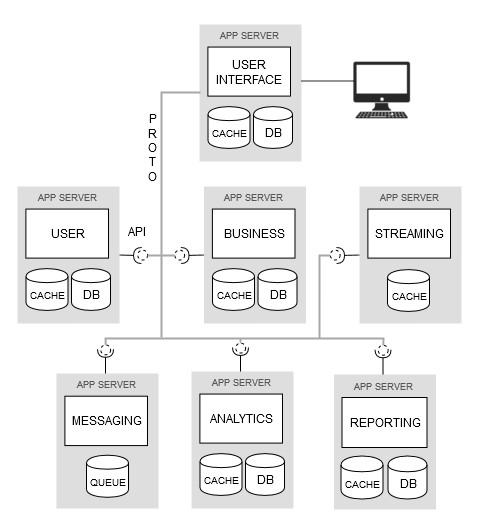
A new emerging architectural style is gaining traction in the software engineering world to overcome all the issues posed by the monolithic approach and commonly known under the name microservices. The idea behind this paradigm is that of decomposing a monolithic application into smaller (micro) distributed parts (services) that are more loosely coupled, that can be independently developed and that interact over a network by means of a lightweight standard protocol using well-defined API. Figure 1.2 shows the same system of Figure 1.1 designed using a microservices architecture.
At first sight it may look a lot like the definition of SOA. And in fact there are countless resources that can be found online (some from prominent figures of the IT world) comparing the two paradigms with different points of view about their scope. Some see it as just a rebranded SOA with a lot of hype, while others consider it an improvement by calling it “SOA done right”, or complimentary with a related but different scope. Whatever the point of view, there are some peculiarities that characterize a microservice architecture.
Fine Granularity
By decomposing a monolithic architecture into smaller entities with limited and well defined scope, individual stand-alone services are created. Each one of these services has a single responsibility in the context of the global business scope.
Autonomy
A microservice is an independent and autonomous entity. Albeit still connected to other microservices through a network, it runs as a separate instance in a separate run-time environment, with its own data storage and code base.
Technical agnosticism
A microservice, being autonomous, is not dependent on a specific technology stack. This means that it is possible to choose the most suitable language, framework, database, etc. to implement it regardless of what other services in the application are using.
Standard lightweight communication
Unlike a monolith service that may use different platform-specific communication techniques (in-process calls, pipes, sockets, OS queues, etc.), a microservice communicates with other services using simple standard protocols and data formats, such as REST/HTTP/JSON.
Well-defined interfaces
Services in monolithic architectures may be implemented in languages that do not explicitly define interfaces, which are then specified through common coding conventions and documentation. Since microservices are developed independently from each other they must expose well defined interfaces (e.g. REST) in order to be reliably used.
Universal identity
Microservices can be located by means of standardized naming, typically in the form of URLs, which makes them universally accessible through standard protocols. This is in contrast to services in monolithic applications that are located using low-level hardware-specific identifiers such as memory and network addresses, port numbers, etc.
Benefits and drawbacks
In a sense, it can be said that microservices are a specialized case of SOA wherein the services are considered in isolation and implemented at a finer level of granularity rather than as a large block of tightly connected components. These characteristics confer substantial advantages over the monolithic approach in the design of complex software systems
- The whole system becomes more efficiently scalable as microservices can be scaled up and down independently in a distributed fashion when there is a real individual need.
- The system is much more fault tolerant since microservices live in separate computing environments thus creating multiple points of failure rather than a single one like in a monolith. Even if one of them completely breaks, it can be simply cut off causing at most only a degradation of the QoS rather than a potential crash of the whole application.
- The code base is not shared among microservices, which means that it is not directly affected by the “noise” (bugs) generated by changes to other services, thus making their development more flexible, quick and reliable.
- Since a microservice is well defined and limited in scope, its code base is smaller and therefore more maintainable, testable and easily extensible, allowing the individual teams to be more focused and productive.
However, microservices have their drawbacks too, and some of them may be quite heavy to the point of making them inconvenient in many cases. Architectures built upon the microservices concept are essentially distributed systems and so they come with all the issues that must be faced when dealing with such systems.
- Communication between services suffer a much higher latency than in a monolith due to the overhead introduced by the network and the abstraction needed to achieve platform-agnosticism.
- Developing and maintaining the inter-service communication infrastructure constitutes an additional burden that may become even bigger than the core service itself if the granularity used to decompose the system is too much fine-grained.
- Performing QA (especially integration testing) is way more complex than in a monolith as distributed systems are notoriously very hard to debug.
- Each microservice is a stand-alone system and needs its own dedicated resources to run (server, container, VM) which makes the resources needed to run the whole system generally much higher than in a monolith, thus increasing the running costs.
- Orchestrating a complex system made up of many independent sub-systems is not a trivial task and requires specialized tools that are not needed in monoliths.
2. Containerization
Containerization is a software development methodology that is making a lot of buzz these days and to fully understand what it is about, along with the benefits that it brings, it is better to start with the concept of virtualization, to which containerization is strongly related.
Virtualization is a computing paradigm that aims at abstracting machine resources in order to optimize their use and gain more operational flexibility. It is the core idea underlying the concept of virtual machine (VM), which represents a full-fledged and self-sufficient computing device implemented in software (an emulated computer, simply speaking) and running on a physical host machine. Multiple VMs can run on the same host computer sharing the same hardware resources. VMs are created from objects, called images, that package together all the components necessary for their operation, such as the OS (the guest OS), applications, dependencies, run-time and configuration files.
The sharing of the underlying hardware resources is made possible by a special component called the hypervisor, which has access to the hardware either through the OS of the host computer (the host OS) or directly, in which case it replaces the host OS altogether. Essentially, it acts as an abstraction layer over the underlying hardware and its task is that of managing the allocation of the shared resources and the life-cycle of the VMs.
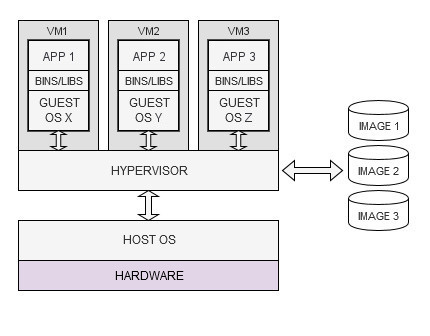
This computing paradigm is called hardware-level virtualization (or simply virtualization) as it creates a virtual operating environment that abstracts away the hardware resources and allows different OS (and thus different VMs) to simultaneously run on the same physical computer. The main benefit of this approach is a more efficient use of computing resources as many different applications, such as data storages, web services, message brokers, etc., even owned by different users, can run in VMs on the same server rather than on separate servers.
Other advantages are better scalability, since it’s cheaper to provision a new VM than a new physical server, portability because VMs are self-contained and can be easily moved to other computers, and security due to the fact that they are fully isolated from the host machine and from one another.
Containerization is a computing paradigm that has its roots in the concepts of virtualization, but uses a different approach. Like a VM, a container represents a self-sufficient and full-fledged computing environment that includes all the necessary resources to run an application and that is instantiated from an image. Unlike a VM, however, it does not include a full OS but rather uses the one in the host computer, which is shared with other containers running on the same machine.
The key component in this model is called the runtime engine, which has a similar role as the hypervisor, that is instantiating and running containers, managing allocation and access to the resources and keeping the containers in isolation. While a VM represents a complete and independent computing system, a container can be seen as an independent user space instance in the host OS (even though it still appears like a dedicated computer to the applications). For this reason, containerization is also called OS-level virtualization.
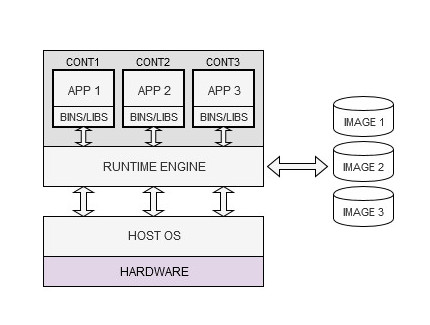
The first consequence of this different approach is immediately evident: containers are much more lightweight than VMs since they do not carry the heavy baggage of an associated OS. This means a faster start up as they avoid the extra overhead of running the guest OS, better scalability since more containers than VMs can be run on the same hardware, and faster computing since they use the host OS directly, thus allowing (near) native performance. They also have better portability because of complete independence from an OS, which is abstracted away by the runtime engine.
However, containers also have at least one major drawback compared to VMs: they are less secure because isolation in containers happens at the process level. A container, in fact, is essentially a running process that uses the shared host OS’ kernel directly (through the runtime engine), meaning that faults (bugs, vulnerabilities) in one container may propagate to the host OS and thus indirectly affecting other containers. In contrast, VMs are shielded by the hypervisor, which represents the hardware and that may make use of hardware features to fully isolate them (VMs are also running processes).
But why is containerization receiving so much attention in the software engineering community? The reason lies first and foremost in portability. It implements the well known paradigm “write once, run anywhere”. A container is an executable run-time environment with an application that is independent from the host OS, which means it can be executed on any platform that has a runtime engine. A bit like a Java program can be execute anywhere there is a JVM, with the difference that a container is not just for Java. It’s for any kind of application written in any language and using any framework.
When doing cross-platform development the curse of what can be called the “portability hell” is a reality that every developer has to deal with. Reproducing a consistent environment across different platforms can be a nightmare and often leads to the same code running with bugs or failing altogether due to inconsistencies between the various platforms. Containers allow to set up the application environment once and package it into a standard format that can be used to easily develop and deploy the code on any computer.
Another benefit of containerization is that it empowers the concept of microservices, that is the decoupling of application functionality from specific technology and runtime artifacts. It also makes the automation of development processes much smoother, thus allowing the implementation of Continuous Integration/Delivery practices. By separating the application from the infrastructure, the whole software development process becomes more efficient and agile.
3. Serverless computing
Since the advent of the cloud-computing paradigm there has been a continuous increase in the level of abstraction over the computing infrastructure used to run software applications. The Infrastructure-as-a-Service (IaaS) and Platform-as-a-Service (PaaS) concepts have provided a means for hiding the complexity of managing hardware resources and run-time environments, respectively, by delegating these responsibilities to third party providers.
This shifting of infrastructure management concerns towards external parties has been pushed even further by what is today called serverless computing. The most common definitions found in the literature can be summarized in “a method of software development that allows building applications without concerns for provisioning servers“. However this definition is a little incomplete and the reason is probably due to its unfortunate naming, which also seems to imply that there are no servers whatsoever (obviously there are, but the developer is “concern-less” about them)
Serverless computing, in fact, abstracts away not only the server systems but also the entire concept of application as a long-running process. The core idea is that of executing small self-contained units of code “in the cloud” on-demand, either asynchronously (triggered by events) or synchronously (by direct requests, such as API calls), without worrying for the underlying computing environment, including the application run-time.
With serverless computing the idea of application is no longer that of a centralized process running on a server waiting for requests but rather that of a distributed set of “functions” that are provisioned and executed in the cloud as needed for a very short time (hereinafter called s-functions, as in “serverless functions”). Both the concern of managing servers and application run-times are offloaded to the cloud providers. In fact, serverless applications can be built using any language without regards for maintenance of the underlying framework.
These s-functions can be implemented and provided by third party vendors for many business cases and used by developers “as a service” to create full-fledged back-ends without writing any server-side code, a paradigm also known as Backend-as-a-Service (BaaS). But these s-functions can also be custom-coded and deployed to the cloud by the developers themselves, enabling the Function-as-a-service (FaaS) concept, which is considered to be the core technology of serverless computing and often used as a synonym.
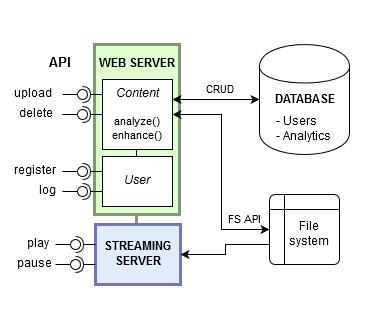
Figure 3.1 shows an example of web application (purposely simplified) developed using a traditional monolithic architecture where users can upload multimedia content and publish it so that other users can see it. A sort of mini YouTube. The application exposes a public API for clients to use and stores data in a RDBMS and in a filesystem.
This application will have at least three long-running processes: a web server for user and content management, a streaming server to deliver content and a database server for data storage. Using this development style the IT team will be responsible for the maintenance of both the OS layer (installing system libraries, configuring services, patching vulnerabilities, etc.) and the application layer (tuning the run-time environment, configuring the web server, optimizing database structures, etc.). It will also be the responsibility of the developers putting in place all the necessary infrastructure to opportunely scale the system as needed.
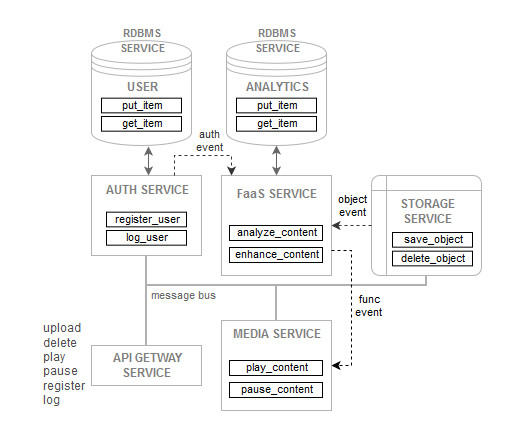
We could design the same system with a serverless approach, like in Figure 3.2. In this architecture, there is no more the concept of application as a set of long-running processes waiting for requests. Instead, the application is now a cluster of distributed s-functions that are instantiated and execute only when needed. Each of this s-function is a stand-alone block of code running in its own environment (usually in a container) and logically grouped with others of related functionality to provide some kind of service.
The communication happens over a message bus and is generally implemented using an event-driven model. There are no OS layers or application run-times to be concerned of, as they are managed by the service provider. All the developers see is a set of distributed and cooperating tasks that must be opportunely orchestrated to achieve the application’s objectives.
With serverless computing the level of abstraction of the underlying infrastructure is taken to its limit of granularity since functions are the base construct to build modular architectures (but I might be wrong and we could one day have XaaS, Instructions-as-a-Service, for distributed CPUs). By having the basic building blocks fully managed and even implemented by a third party (as in BaaS) there may be considerable savings in terms of running costs and development time, allowing teams to focus solely on the business logic of the application.
Another benefit is the fact that resources are more efficiently used since there is no long-running process that must be maintained permanently even when the application receives no requests. As a consequence, developers can only pay for the resources used when the s-functions are actually invoked and not for idle time. Also, the application is more easily and efficiently parallelizable and scalable since this can be done at a finer level of granularity (the s-functions) and is totally taken care of by the service provider.
One of the major drawbacks of serverless computing is high “vendor lock-in” risk as applications developed using this paradigm are strongly coupled to the native infrastructure of the service provider, which often has little interest to incentivize portability. Since the design and implementation typically follows a microservices paradigm, serverless computing comes with all of its drawbacks. More complexity, higher latency, more difficult monitoring, testing and debugging of the system as a whole and higher costs of maintenance. These aspects may be worsened by poor design decisions that lead to excessive granulation of the s-functions, and hence to even greater complexity and burdens.
A serverless approach is also not suitable for high-performance mission-critical applications because serverless functions may introduce unacceptable latency caused by “cold startups”, that is re-initializations of the run-time environments (typically containers) since they might not be reused between calls. Serveless functions are also subjected to CPU and memory usage restrictions, which may be a severe bottleneck for such applications. For these use cases, a traditional always-ready long-running process is usually a better choice.
4. Continuous Integration, Delivery & Deployment
As software systems increase in size at exponential rates, so does the difficulty of making changes to their architecture while assuring correctness and adherence to business needs. In highly complex software applications even the smallest modification to the code made by a single developer can lead to bugs that propagate system-wide and that are hard to catch. And when there is a whole team simultaneously working on the same code base, the integration of all the changes into the shared copy can easily turn into a nightmare if not properly planned.
This integration issues dramatically amplify the bigger the team, requiring an immense effort of continuous building, testing and fixing in order to eliminate regressions and keep the code base in a continuous deployable state. If this iterative process of coding, building, testing and deploying is not seamless the resulting SDLC can suffer tremendously leading to increased development times and poor adaptability to changes.
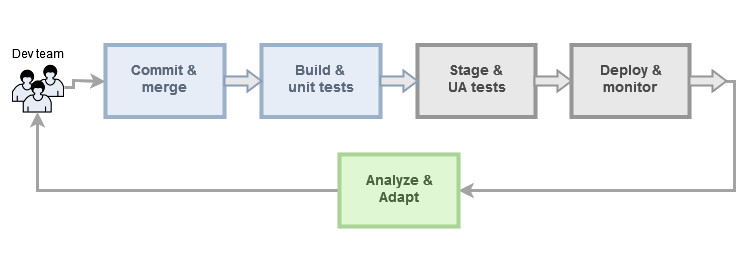
A set of practices are gaining a lot of popularity in modern software development that aim at reducing to the bare minimum the friction between the various steps in the pipeline and that go under the names of continuous integration, continuous delivery and continuous deployment.
Continuous integration (CI) aims at improving the way software is produced by avoiding the issues arising from merging changes that are overly out of sync with the master (a situation also known as the “integration hell”). This usually happens when the developers’ working copies are too long-lived and cause lots of conflicts when merged with the shared copy. Generally, the longer the time before merging the local changes the higher the chance of conflicts and bugs, which can only be discovered when a scheduled build and test are performed. Or, worse, in production!.
Instead, with a CI approach the developers are tasked with small units of work that are short-lived (can be completed quickly) and continuously integrated into the master branch triggering the automatic build and testing of the code base. The rationale is that by integrating the working copies more frequently and having them automatically built and tested, bugs can be caught early before they subtlety infiltrate the system. This also keeps the surface of remediation much smaller in case of fixes since the amount of code to be reworked is small, making it easier to write well designed corrections rather than quick hacky solutions due to lack of time, with obvious benefits for the code quality.
For this strategy to work properly, however, there must be robust and comprehensive automation infrastructure in place, both for integrating and testing, otherwise the frequent integrations will create too much friction in the development process. A typical CI pipeline is shown in Figure 4.2
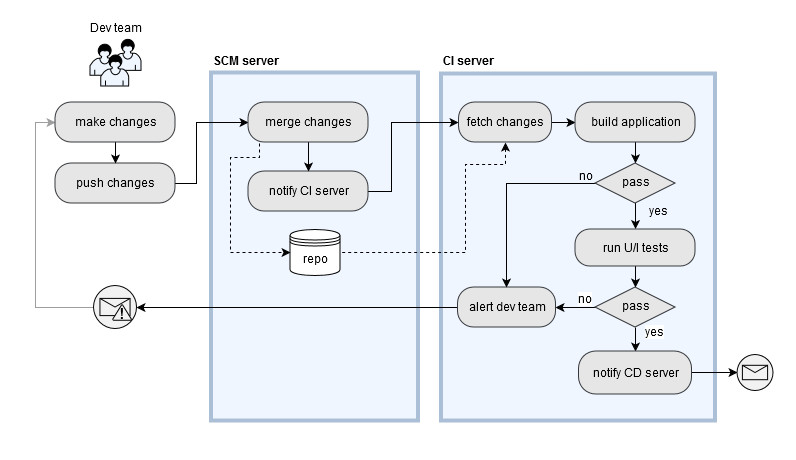
When a developer merges his working copy to the master branch, the SCM server notifies the CI server, which fetches the updated code base, builds it and runs unit and integration tests. If any issues arise, then the developers are immediately alerted so that they can remediate the problem right away. CI’s main concern is, in fact, that of continuously assuring the structural sanity of the system and the quality of the code. It also keeps the developer focused on the current task until it is fully working, thus avoiding the “context switch” that would occur if the feature were found to be buggy at a later time.
Continuous Delivery (CD), in its more general conception, can be seen as a complement of CI for the deployment and release phases aiming at making the changes available to the end users as quickly as possible. After the CI phase, where the updated code is structurally tested for correctness and assured to be bug free, further tests are carried out to verify the functional adherence of the whole system to the specifications.
This is done by conducting system tests and UA tests at different stages (where each stage is usually called a release/deployment pipeline). The number of pipelines in CD may vary depending on the business and the application, but often there is a packaging stage where all the build artifacts from the CI pipeline are assembled together to form the application and where system tests are performed, and a staging pipeline that recreates as closely as possible the production environment for user acceptance tests.
Once the new changes are determined to be adherent to the business requirements by passing all the tests, the system can be considered to be “production ready” and can be officially released to the end users. At this point in the pipeline, a decisional entity (typically the management) will trigger the deployment of the updated system to production.
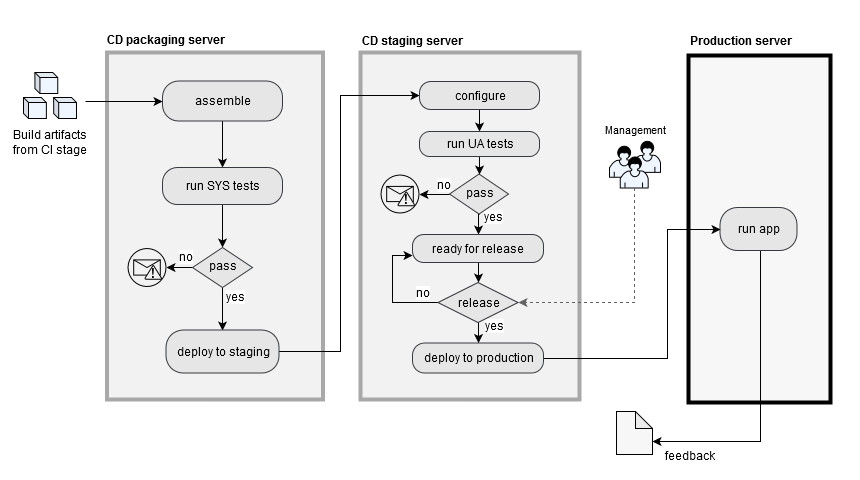
As with CI, the key ingredient of CD is the heavy use of automation throughout the pipeline that makes the whole process lean and agile. The main concern of CD is that of shortening as much as possible the path from the integration of changes to the release to the end users by assuring adherence of the functionalities to the business scope and have a code base that is deployable at any time.
Continuous Deployment (CD) is generally seen as a variant of continuous delivery. It has the same concern, that is having changes fully accepted and ready for production as quickly as possible. But it is differentiated from continuous delivery in that the updated system is immediately released into production without waiting for a decision-making entity to trigger the deployment.
With continuous deployment there is a fully automated direct path from committed changes in the code base to the end user in production. A consequence of this approach is that the lack of an entity approving the releases, as in the continuous delivery case, makes the responsibility totally shift towards the development team, which has to adopt appropriate practices in order to assure that the changes can be safely put into production. This, however, can be a positive aspect as it may work as an incentive to enforce discipline within the team.
The benefits of adopting a CI/CD strategy in software development can be summarized in more lightweight and fluent cycles (lean processes), reduced development times (faster iterations, as a consequence), and an overall increased responsiveness of the team to changes through early feedback.
There are, however, some drawbacks too. First of all the necessity to develop and maintain the necessary code for the automation of processes, the provisioning of the CI/CD infrastructure and the mental friction that may derive from the adoption of new approaches over established (legacy) practices. Nonetheless, the benefits of following these new paradigms generally outweigh all the inconveniences.
As usual in software engineering, there are different schools of thought on these subjects, and different points of view and definitions can be found in the field. However, an underlying common philosophy can be abstracted away: CI/CD simply represent a natural evolution of the traditional SDLC, based on bulky approaches and burdened by too many manual processes, into a more agile strategy, which is required to tackle the complexity of modern systems and the rapid pace at which businesses must respond to customers’ needs.
Conclusion
There is a lot of discussion in the industry about whether these methods are really something new. Undoubtedly, they are surrounded by a lot of hype, greatly fueled by software vendors that are using these terms as buzzwords to market their latest cool product. But we software engineers should not fall for these tricks and be able to rationally filter out the hype from the true essence of things.
While it is true that all of the emerging practices discussed here are based on, or inspired to, concepts that have been around for quite some time (and many in the industry seeing them as just hyped revisiting of old paradigms), it is also true that modern systems cannot be tackled with legacy rigid approaches. Creating mental barriers is the biggest roadblock for innovation.
Often times all it takes to create something that is suitable to current needs is just slight variations to old models, or new tools that allow existing models to be more efficiently used. After all, modern software development should be seen as anything that allows to effectively deal with the complexity of modern systems, regardless of the level of novelty.